Data Science Course Syllabus 2024
This cutting-edge data science course in 2024 is designed to equip students with the latest tools and techniques in the field. The syllabus covers essential areas such as statistical modeling, machine learning, and data visualization, emphasizing practical applications through hands-on projects. Topics include data cleaning, exploratory data analysis, and ethical considerations in data science. Students will also gain proficiency in utilizing advanced tools for large-scale data processing.
Keep in mind that specific courses may vary based on the institution and instructor. Additionally, advancements in technology and changes in the field may result in modifications to the syllabus. Here’s a comprehensive outline.
Introduction to Data Science
What is Data Science?
Data science combines math and statistics, specialized programming, advanced analytics, artificial intelligence (AI), and machine learning with specific subject matter expertise to uncover actionable insights hidden in an organization’s data. These insights can be used to guide decision making and strategic planning.
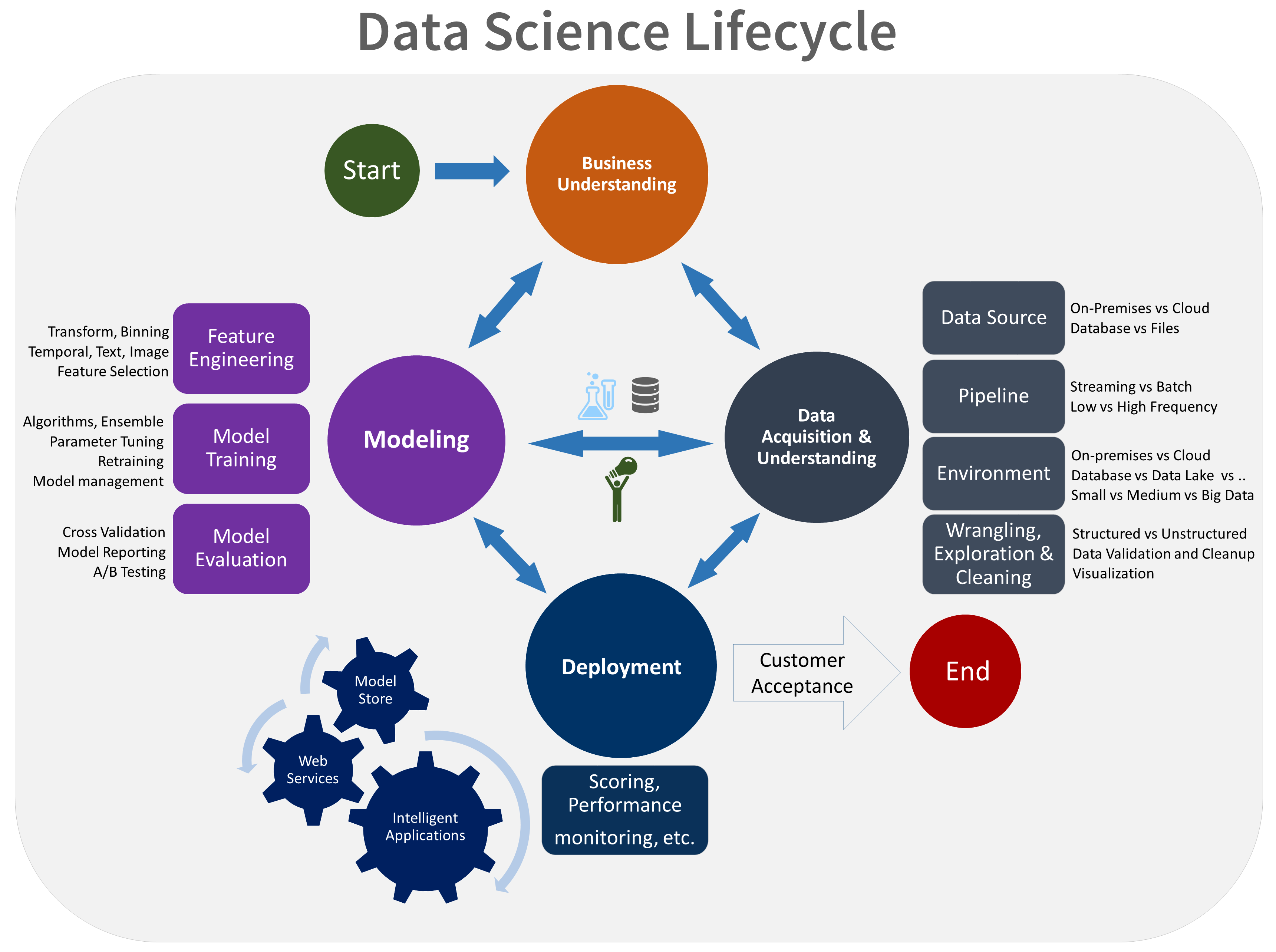
Overview of the Data Science Lifecycle
A data science lifecycle is defined as the iterative set of data science steps required to deliver a project or analysis. There are no one-size-fits that define data science projects. Hence you need to determine the one that best fits your business requirements. Each step in the lifecycle should be performed carefully.
Role of a Data Scientist
A Data Scientist is a proficient specialist who applies mathematical, problem-solving, and coding skills to manage big data, extracting valuable insights. They design tailor-made solutions from this data, aiding organizations in achieving their unique objectives and goals.
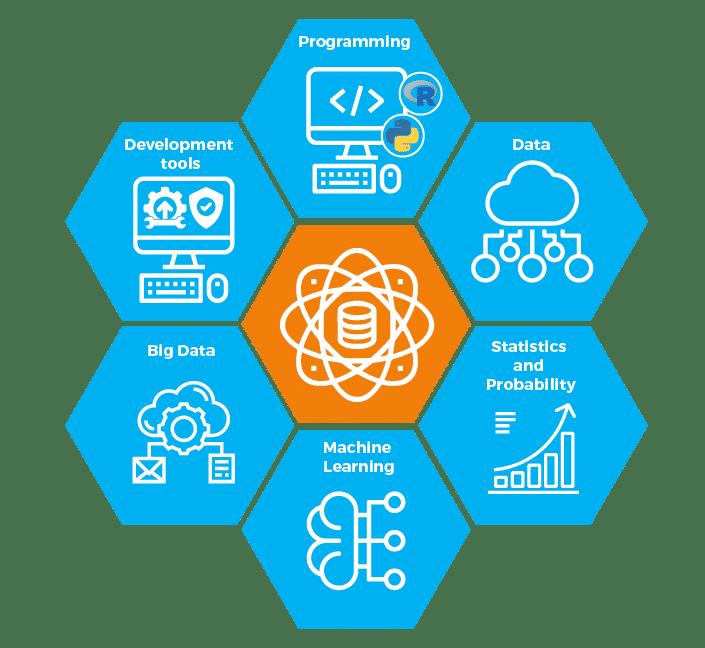
Programming and Tools for Data Science
Introduction to Programming Languages
A programming language is a set of symbols, grammars and rules with the help of which one is able to translate algorithms to programs that will be executed by the computer. The programmer communicates with a machine using programming languages. Most of the programs have a highly structured set of rules.
Eg:Python, R
Version Control with Git
Version control is a system that records changes to a file or set of files over time so that you can recall specific versions later. For the examples in this book, you will use software source code as the files being version controlled, though in reality you can do this with nearly any type of file on a computer.
Data Science Libraries
Pandas
Pandas is a software library written for the Python programming language for data manipulation and analysis. In particular, it offers data structures and operations for manipulating numerical tables and time series. It is free software released under the three-clause BSD license
NumPy
NumPy is a library for the Python programming language, adding support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays.
SciPy
SciPy is a free and open-source Python library used for scientific computing and technical computing. SciPy contains modules for optimization, linear algebra, integration, interpolation, special functions, FFT, signal and image processing, ODE solvers and other tasks common in science and engineering.
Matplotlib
Matplotlib has powerful yet beautiful visualizations. It’s a plotting library for Python with around 26,000 comments on GitHub and a very vibrant community of about 700 contributors. Because of the graphs and plots that it produces, it’s extensively used for data visualization. It also provides an object-oriented API, which can be used to embed those plots into applications.
TensorFlow
The first in the list of python libraries for data science is TensorFlow. TensorFlow is a library for high-performance numerical computations with around 35,000 comments and a vibrant community of around 1,500 contributors. It’s used across various scientific fields. TensorFlow is basically a framework for defining and running computations that involve tensors, which are partially defined computational objects that eventually produce a value.
Plotly
With over 50 million users globally, Plotly is an open-source Python 3D data visualization framework. It’s a web-based data visualization tool built on the Plotly JavaScript library (plotly.js). Plotly supports scatter plots, histograms, line charts, bar charts, box plots, multiple axes, sparklines, dendrograms, 3-D graphs, and other chart types. Plotly also includes contour plots, distinguishing it from other data visualization frameworks.
Scikit-learn
Next in the list of the top python libraries for data science comes Scikit-learn, a machine learning library that provides almost all the machine learning algorithms you might need. Scikit-learn is designed to be interpolated into NumPy and SciPy.
Seaborn
Another popular Matplotlib-based Python data visualization framework, Seaborn is a high-level interface for creating aesthetically appealing and valuable statistical visuals which are crucial for studying and comprehending data. This Python library is closely connected with both NumPy and pandas data structures.
PyTorch
Next in the list of top python libraries for data science is PyTorch, which is a Python-based scientific computing package that uses the power of graphics processing units. PyTorch is one of the most commonly preferred deep learning research platforms built to provide maximum flexibility and speed.

Data Exploration and Visualization
Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) refers to the method of studying and exploring record sets to apprehend their predominant traits, discover patterns, locate outliers, and identify relationships between variables. EDA is normally carried out as a preliminary step before undertaking extra formal statistical analyses or modeling
Data Cleaning and Preprocessing
Data Cleaning Process. Data cleaning, a key component of data preprocessing, involves removing or correcting irrelevant, incomplete, or inaccurate data. This process is essential because the quality of the data used in machine learning significantly impacts the performance of the models.
Visualization Techniques
Data visualization is a critical component of data science, serving as a powerful means to communicate insights from complex datasets. In this module, we explore key visualization libraries such as Matplotlib, Seaborn, and Plotly.
Statistical Concepts for Data Science
![]()
![]()

Descriptive Statistics
A descriptive statistic is a summary statistic that quantitatively describes or summarizes features from a collection of information, while descriptive statistics is the process of using and analyzing those statistics.
Descriptive statistics examples in a research study include the mean, median, and mode. Studies also frequently cite measures of dispersion including the standard deviation, variance, and range. These values describe a data set just as it is, so it is called descriptive statistics.
Inferential Statistics
Statistical inference is the process of using data analysis to infer properties of an underlying distribution of probability. Inferential statistical analysis infers properties of a population, for example by testing hypotheses and deriving estimates.
The process of using a random sample to draw conclusions about a population is called statistical inference. If we do not have a random sample, then sampling bias can invalidate our statistical results. For example, birth weights of twins are generally lower than the weights of babies born alone.
Probability Distributions
In probability theory and statistics, a probability distribution is the mathematical function that gives the probabilities of occurrence of different possible outcomes for an experiment. It is a mathematical description of a random phenomenon in terms of its sample space and the probabilities of events.
Hypothesis Testing
A statistical hypothesis test is a method of statistical inference used to decide whether the data at hand sufficiently support a particular hypothesis. More generally, hypothesis testing allows us to make probabilistic statements about population parameters.
Machine Learning Fundamentals

Introduction to Machine Learning
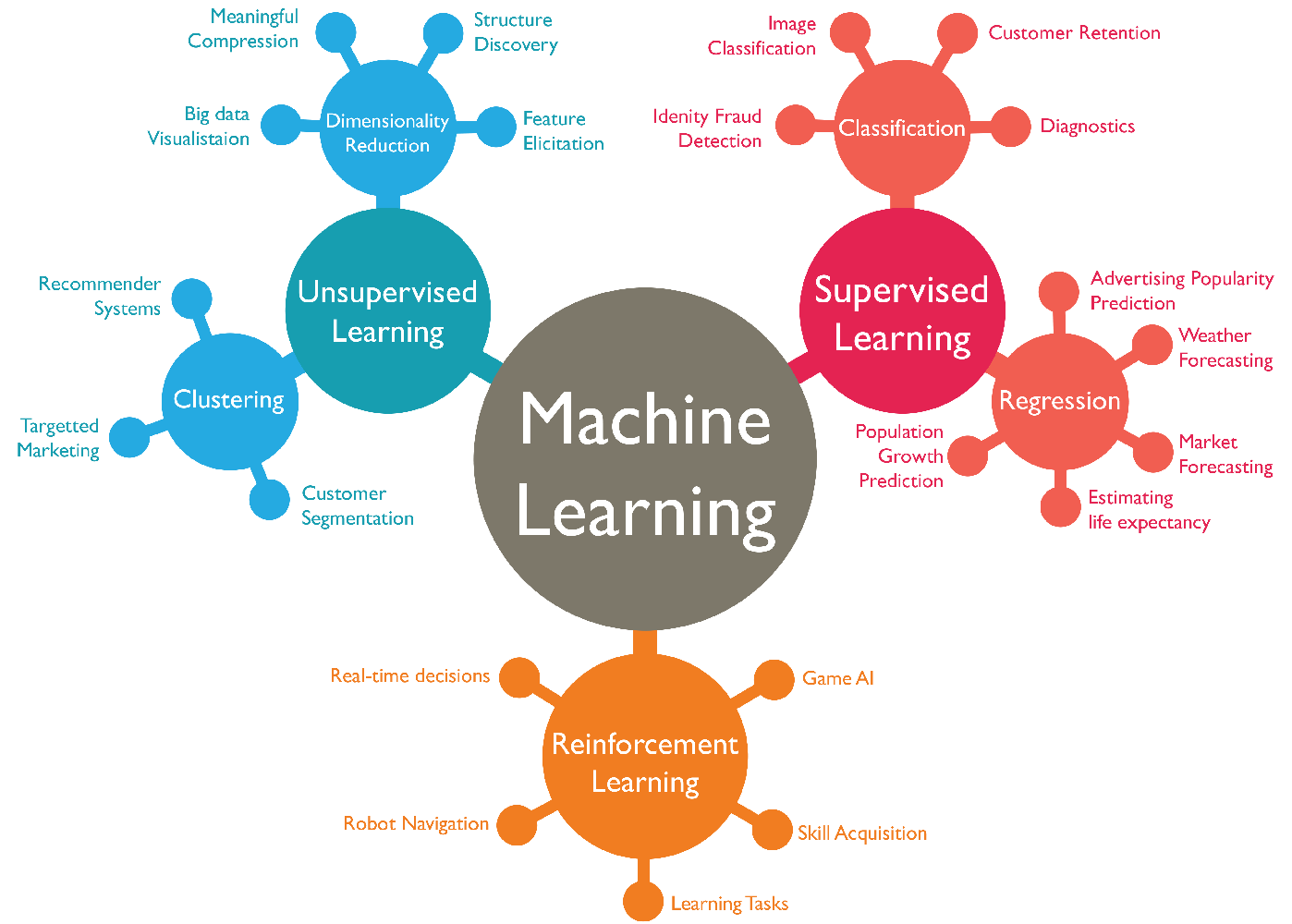
Machine learning (ML) is a branch of artificial intelligence (AI) that enables computers to “self-learn” from training data and improve over time, without being explicitly programmed. Machine learning algorithms are able to detect patterns in data and learn from them, in order to make their own predictions.
Supervised Learning, Unsupervised Learning, and Semi-Supervised Learning
Supervised learning is a problem with labeled data, expecting to develop predictive capability. Unsupervised learning is a discovery process, diving into unlabeled data to capture hidden information. Semi-supervised learning is a blend of supervised and unsupervised learning.
Model Evaluation and Selection
Model Selection and Evaluation is a hugely important procedure in the machine learning workflow. This is the section of our workflow in which we will analyze our model. We look at more insightful statistics of its performance and decide what actions to take in order to improve this model.
Feature Engineering
Feature engineering is a machine learning technique that leverages data to create new variables that aren’t in the training set. It can produce new features for both supervised and unsupervised learning, with the goal of simplifying and speeding up data transformations while also enhancing model accuracy.
Advanced Machine Learning Techniques
Ensemble Learning
Ensemble learning is a machine learning technique that enhances accuracy and resilience in forecasting by merging predictions from multiple models. It aims to mitigate errors or biases that may exist in individual models by leveraging the collective intelligence of the ensemble.
Dimensionality Reduction
Dimensionality reduction, or dimension reduction, is the transformation of data from a high-dimensional space into a low-dimensional space so that the low-dimensional representation retains some meaningful properties of the original data, ideally close to its intrinsic dimension.
Hyperparameter Tuning
Hyperparameter tuning allows data scientists to tweak model performance for optimal results. This process is an essential part of machine learning, and choosing appropriate hyperparameter values is crucial for success. For example, assume you’re using the learning rate of the model as a hyperparameter.
Introduction to Neural Networks and Deep Learning
A neural network is a method in artificial intelligence that teaches computers to process data in a way that is inspired by the human brain. It is a type of machine learning process, called deep learning, that uses interconnected nodes or neurons in a layered structure that resembles the human brain.
Big Data Technologies
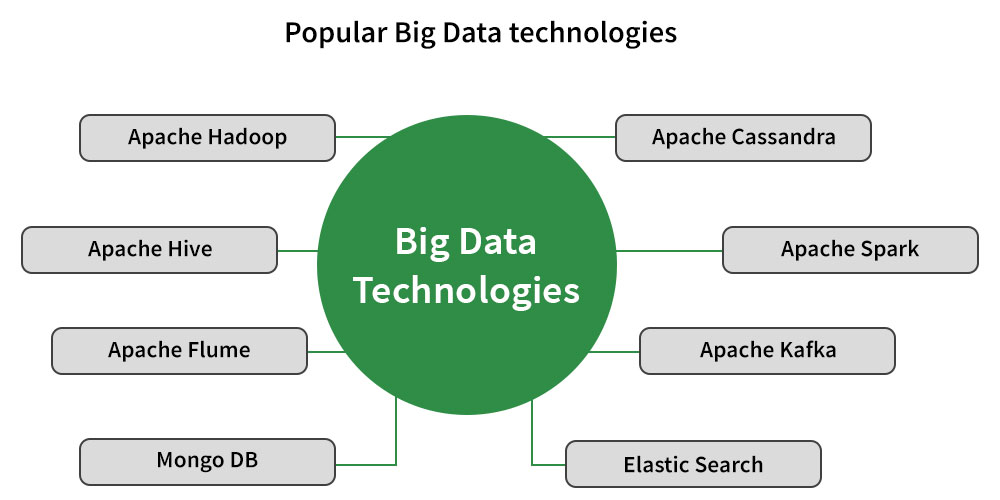
Introduction to Big Data
Big data is a collection of massive and complex data sets and data volumes that include huge quantities of data, data management capabilities, social media analytics and real-time data. Big data analytics is the process of examining large amounts of data.
Hadoop and MapReduce
Apache Hadoop is a software that allows all the distributed processing of large data sets across clusters of computers using simple programming.
MapReduce is a programming model which is an implementation for processing and generating big data sets with distributed algorithms on a cluster.
Apache Spark
Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark provides an interface for programming clusters with implicit data parallelism and fault tolerance.
Distributed Computing
Distributed computing is the method of making multiple computers work together to solve a common problem. It makes a computer network appear as a powerful single computer that provides large-scale resources to deal with complex challenges.
Database Management and SQL

Relational Databases
A relational database is a type of database that stores and provides access to data points that are related to one another. Relational databases are based on the relational model, an intuitive, straightforward way of representing data in tables.
SQL (Structured Query Language)
Structured query language (SQL) is a programming language for storing and processing information in a relational database. A relational database stores information in tabular form, with rows and columns representing different data attributes and the various relationships between the data values.
NoSQL Databases
NoSQL databases are designed for a number of data access patterns that include low-latency applications. NoSQL search databases are designed for analytics over semi-structured data. Data model. The relational model normalizes data into tables that are composed of rows and columns.
Data Engineering
Extract, Transform, Load (ETL) Processes
Extract, transform, and load (ETL) is the process of combining data from multiple sources into a large, central repository called a data warehouse. ETL uses a set of business rules to clean and organize raw data and prepare it for storage, data analytics, and machine learning (ML).
Data Warehousing
A data warehouse is an enterprise system used for the analysis and reporting of structured and semi-structured data from multiple sources, such as point-of-sale transactions, marketing automation, customer relationship management, and more. A data warehouse is suited for ad hoc analysis as well custom reporting.
Data Pipeline Architecture
Data pipeline architecture is the design and structure of code and systems that copy, cleanse or transform as needed, and route source data to destination systems such as data warehouses and data lakes.
Data Ethics and Privacy

Ethical Considerations in Data Science
In summary, ethical considerations in data collection are about ensuring respect, fairness, and responsibility in the way data is handled, balancing the needs and objectives of data collection with the rights and welfare of individuals.
Privacy and Security
In the digital world, security generally refers to the unauthorized access of data, often involving protection against hackers or cyber criminals. Privacy involves your right to manage your personal information, and security is the protection of this information. Both are equally important aspects of cyber safety.
Responsible AI Practices
The development of AI has created new opportunities to improve the lives of people around the world, from business to healthcare to education. It has also raised new questions about the best way to build fairness, interpretability, privacy, and safety into these systems.
Case Studies and Real-World Applications
Industry-specific Case Studies
Case studies help expose individuals to previous problems and what it took to revise them. They’re useful in training new employees or showing potential clients what an agency is capable of. However, they require a specific structure to be effective.
e.g., Healthcare, Finance, E-commerce
Practical Applications of Data Science
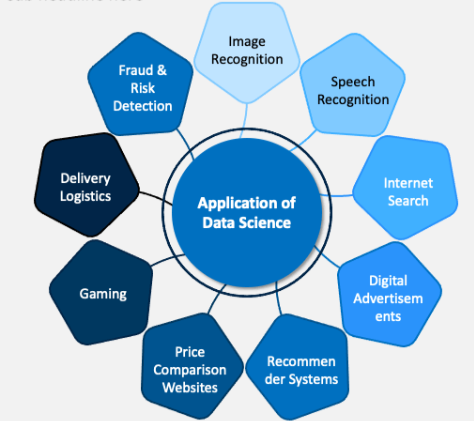
Data science is used for a wide range of applications, including predictive analytics, machine learning, data visualization, recommendation systems, fraud detection, sentiment analysis, and decision-making in various industries like healthcare, finance, marketing, and technology.
Guest Lectures from Industry Professionals
Guest lectures by industry experts are a valuable source of learning for students who want to gain a deeper understanding of their field. Guest lecturers can provide the following benefits to students: – They can share their real-world experiences and challenges in their domain, and how they overcome them.
Capstone Project
Collaborative Project Work
Project collaboration enables entire teams to work together through the entirety of the process. It allows them to be more productive and more aware of each other’s perspectives, needs, and timelines. Even if a team member is across the world, they can still be looped in and contributing.
Problem Statement Definition
A statement of the problem is used in research work as a claim that outlines the problem addressed by a study. A good research problem should address an existing gap in knowledge in the field and lead to further research.
Data Collection, Analysis, and Presentation
Data analysis involves processing and analyzing the data to derive meaningful insights, while data interpretation involves making sense of the insights and drawing conclusions. Data presentation involves presenting the data in a clear and concise way to communicate the research findings.
Final Presentations and Review
Presentation of Capstone Projects
A capstone presentation is an opportunity for a college student to demonstrate his knowledge of the course topic, his field of study or his educational institution. The culminating presentation, typically based on a research paper, is given before a school committee, a board of professors or a classroom of peers.
Review of Key Concepts
The definition of a concept review is the initial idea for a new product or feature and its implementation. A concept review is a process of evaluating different and sometimes competing concepts to figure out which ones an organization should invest in and build to completion.
Future Trends in Data Science
Collaborations with Domain Experts: In the future, data scientists will increasingly collaborate with domain experts in fields such as healthcare, finance, and climate science. This partnership will allow data scientists to apply their skills to real-world problems, enhancing decision-making and problem-solving.
This Data Science Course syllabus is a broad overview, and specific courses may include additional topics or adjust the order of presentation. The emphasis on hands-on projects, real-world applications, and industry perspectives is crucial for preparing students for a career in data science.